1. RNN 데이터입력을위한데이터로더구현
1) field 지정
(1) torchtext를 이용한 field 객체 생성

- 자연어 처리에서 텍스트 데이터를 가지고, 긍부정을 나누는 형태
- torchtext 라이브러리는 파이토치 환경에서 자연어 처리의 전처리, 데이터 분리 등 편리한 기능 제공
- filed를 생성할 예정인데, 여기에 text와 label 값을 넣을 예정.
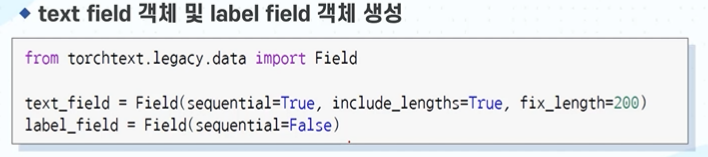
- text : 영화 평
- label : 긍/부정
- sequntial :
> RNN계열은 sequntial 사용 예정.
> sequntial 데이터란 시간적 흐름에 의미가 있거나, 자연어와 같은 선후관계가 존재하는 것.
> 영화평은 자연어가 선후관계가 존재 함.
- include_lengths :
> 길이를 맞추는 여부
> 문장이 길면 자르고, 짧으면 padding 예정
- fix_length = 200
> 길이를 200으로 고정함.
2) 데이터 세트 생성
(1) torchtext를 이용한 IMDB 데이터 세트 로드

- IMDB를 사용해서 train. test 분리 함.

- 실제 잘 담겨있나 확인.
3) vocabulary 생성
(1) text field와 label field vocabulary


- 텍스트 저장된 값으로 vocabulary 생성하여, Embedding 할 예정.
- 이때 사전 정의된 학습 예정.
- vecrors = 'fasttext.simple.300d' 라는 pre_trained 임베딩 모델을 사용할 예정.
- label_field_build_vocab에는 긍,부정만 들어있기에 사전 학습 필요가 없음.
- 추후에 pre_trained 임베딩 모델 bert를 사용할 때, 임베딩, 토크나이징을 할 때 우리가 직접 vocabulary, 토크나이정을 하지 않아도 사전 훈련된 성능이 좋은 것을 쉽게 사영할 수 있음
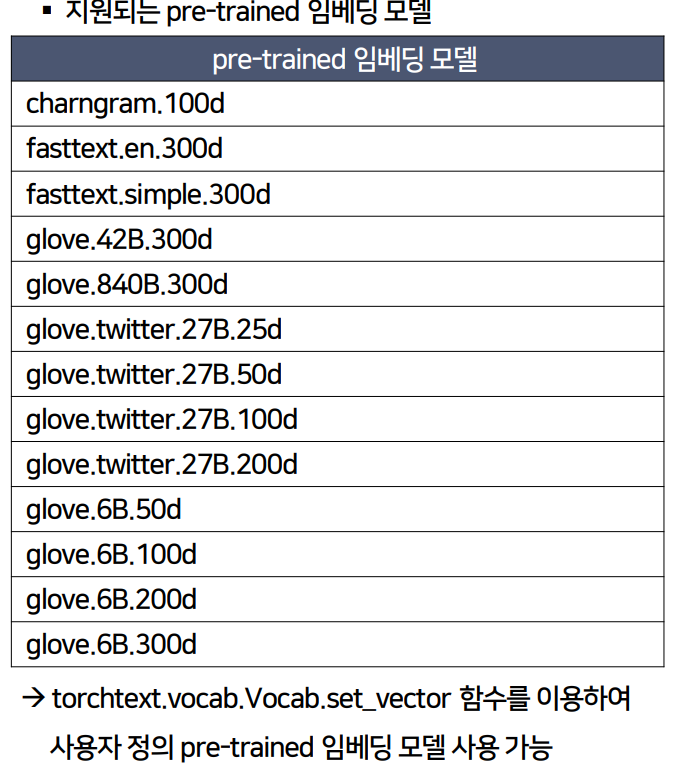
- 다양한 pre-trained 임베딩 모델 리스트
- 6B : 60억 개
- 300d : Dimension
- set_vector : 사용자가 정의한 임베딩 모델을 사용할 수 있음.
4) 데이터 로더 구현
(1) BucketIterator 클래스를 이용한 데이터 로더 구현

- 추후에 Bert사용할 때에도 데이터 세트 클래스를 이용해서, 그 객체를 이용해서 데이터 로더를 이용 함.
- 데이터 로더 중 우린 BucketIterator를 사용함.
- device : gpu, cpu 사용 여부 묻는 code
- bactch_size : 1번 주기 동안의 batch 사이즈 정의.
- BucketIterator :
> 하나의 집합 단위에 이터레이션 수행하면서 batch사이즈 만큼 데이터를 추출해서 입력데이터로 활용하기 위함.
* 이터레이션(Iteration) : 결과를 생성하기위한 프로세스의 반복
> 중요 파라미터가 batch_size임
'🥾 프로젝트 > (STEP)파이썬을 활용한 인공지능 자연어 처리' 카테고리의 다른 글
| 6-1회차) 자연어 처리를 위한 Transformer 적용 (0) | 2023.05.10 |
|---|---|
| 5-2회차) 자연어 처리를 위한 RNN (0) | 2023.05.07 |
| 4-3회차) 자연어 처리를 위한 토픽 모델링 (0) | 2023.05.04 |
| 4-2회차) 자연어 처리를 위한 토픽 모델링 (0) | 2023.05.04 |
| 4-1회차) 자연어 처리를 위한 토픽 모델링 (0) | 2023.05.04 |



