1. 2개 데이터 병합 방법
1) 인기있는 식당의 기준을 네이버 평점 4.5 이상 식당으로 정의 함.
(1) 추후 회귀 모델로 네이버 평점 4.5이상 식당들의 특징을 살펴 볼 예정.
2) 2개의 (전라남도_식당정보, 전라남도_식당품질정보) 파일에는 target변수인 '네이버 평점'과 merge 할 수 있는 고유 '식당 ID'가 존재
3) '식당 ID'로 merge결과 공통된 식당 데이터는 20개만 존재
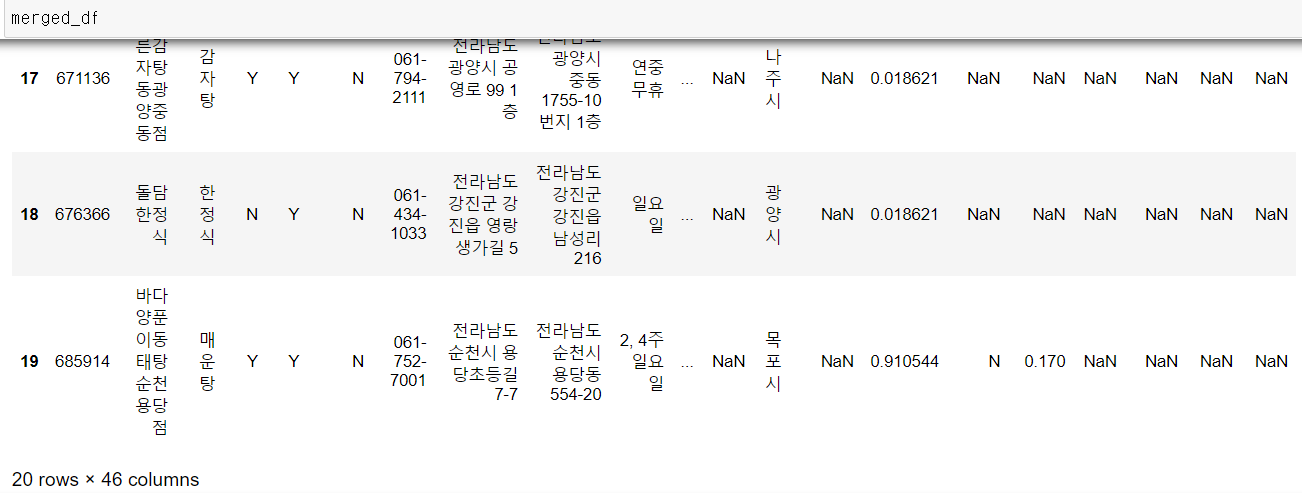
4) '전라남도_식당품질정보' 파일은 이미 평점이 좋은 식당만 존재 & null 값 다수
(1) 네이버 평점 분포가 고루 있어야 인기있는 식당의 특징 파악이 좋으나, 이 파일은 평점이 좋은 식당만 다수
(2) 근거
- 컬럼 '어워드 정보설명' : 모범식당, 안심식당 // 이미 좋은 식당으로 선정된 식당들의 데이터
- 컬럼 '수용태세지수' : 지역별 음식관광 수용태세를 정확히 판단하고 비교하기 위한 수단 // 좋은 점수 받은 식당 데이터
· 참조 : (논문) 지역음식관광 발전을 위한 음식점 수용태세지수 개발: 델파이 기법 및 AHP를 활용하여
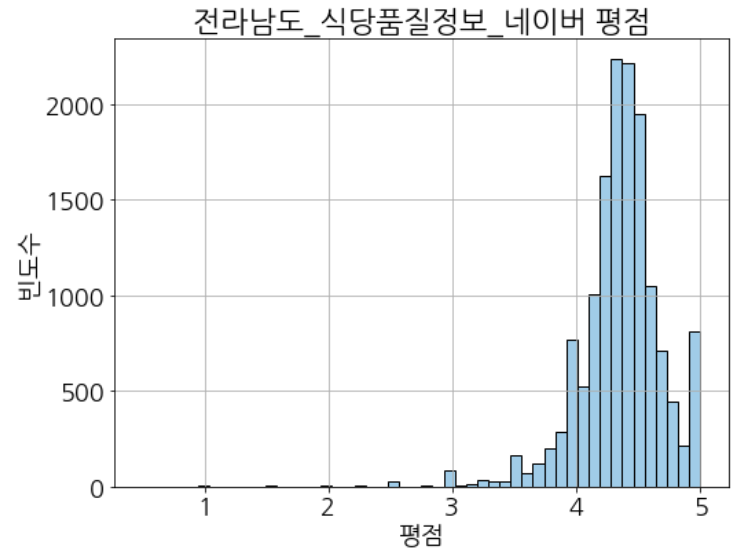
(3) 네이버 평점 분포 확인
- 대부분 4.5 이상 평점으로 분포
(4)
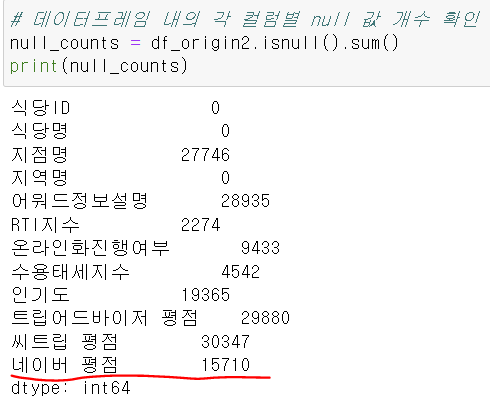
null값 확인
- target이 되는 네이버 평점의 null값이 50%이상 존재.
5) '잔라남도_식당품질정보' 파일은 사용하지 않기로 결정.
(1) 추후 새로운 데이터 확보가 된다면, 업데이트 예정.
앞으로 할 일
1. '전라남도_식당정보' 파일 EDA 실시.
- 컬럼들 특징 파악
반응형
'🥾 프로젝트 > 어떤 식당들이 인기가 좋을까?' 카테고리의 다른 글
| 3) 식당 정보 EDA(3) (0) | 2023.12.31 |
|---|---|
| 3) 식당 정보 EDA(2) (0) | 2023.12.31 |
| 3) 식당 정보 EDA(1) (0) | 2023.12.31 |
| 1) 주제 선정 & 자료 찾기 (0) | 2023.12.25 |



