한글 자연어 전처리 개요
1. 토큰화
- 영문 자연어 전처리와 비슷
- 한글은 형태소, subword 단위로 토큰화 하는 게 성능이 좋다.
2. 불용어 제거
- 한글 경우에는 스스로 환경에 맞는 불용어를 정의하고 제거하는 방식으로 해야 함.
한글 자연어 전처리 적용
1. 정제
- 특수문자 제거
- 영문과 같은 과정
- 정규식을 이용한 특수문자 제거

- 띄어쓰기가 중요한 한글
1) 띄어쓰기가 적용되지 않은 상태로 코퍼스변환
* 정규식을 이용하여 띄어쓰기가 적용되지 않은 상태로 코퍼스 변환

2) 띄어쓰기 적용을 위한 PyKoSpacing 패키지 설치
* PyPi.org에 등록되지않은 상태이므로 git을 이용한 설치
* 실습하려면 구글 colab을 통해 설치.

3) PyKoSpacing을 이용한 띄어쓰기 적용.
* spacing()함수를 이용하여 띄어쓰기 적용.

2. 토큰화
- kss : 한글 문장 단위 토큰화
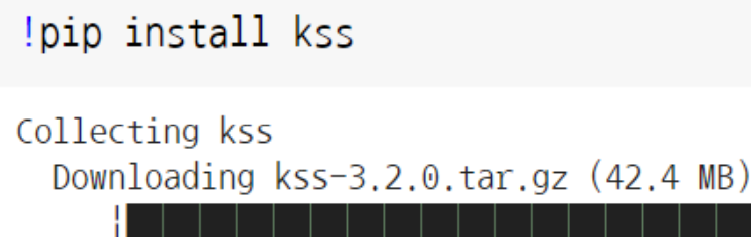
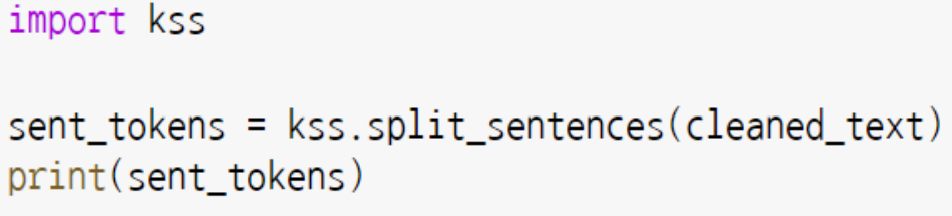
- kss.split_sentences() : 한글 문장단위 토큰화 적용.
- 한글 단어 단위 토큰화
1) 여기서는 가장 간단한 띄어쓰기 기준인 어절 토큰화 보여줄 예정.
2) split() : 아무것도 적지 않으면, 공백 단위로 나눠서 리스트 형태로 출력

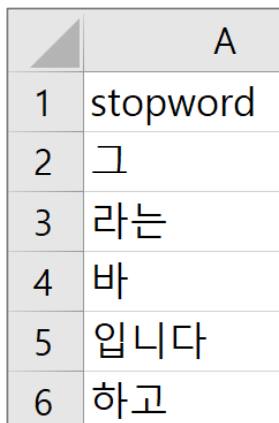
3. 한글 불용어 제거
- 한글 불용어 목록을 제공하지 않고, 인터넷에 다운로드&추가 정리해야 함.
- 여기서는 stopword_dict.csv 파일을 생성할 예정.
- colab업로드 과정 소스.

- pandas을 이용하여 불영어 사전 출력

1) 윈도우 환경에서는 encoding = 'cp949' 되어 있으므로, 이거로 읽어야 함.
2) Dataframe 형태로 저장되어 있음.
- list 타입으로 저장

- 파이썬의 List Compregension을 이용하여 불용어 제거

'🥾 프로젝트 > (STEP)파이썬을 활용한 인공지능 자연어 처리' 카테고리의 다른 글
| 3-2회차) 자연어 처리를 위한 Word2Vec (0) | 2023.05.03 |
|---|---|
| 3-1회차) 자연어 처리를 위한 Word2Vec (0) | 2023.05.03 |
| 2-2회차) 자연어 처리 형태소 분석 (형태소 분석 사전활용) (0) | 2023.01.21 |
| 2-1회차) 자연어 처리 형태소 분석 (영문, 한글 형태소 분석) (0) | 2023.01.18 |
| 1-1회차) 인공지능 자연어 전처리 (영문 자연어 전처리) (0) | 2023.01.15 |



