Pre-trained Word2Vec 모델활용
1. 한글 모델
1) Pre-trained Word2Vec 모델 다운로드
(1) 코랩에서 파일 불러오기


- 한국 전체 방대양 WIKI 데이터 세트를 미리 학습한다면, OOV 해결 및 적절한 유사도 가능.
- 이러한 것이 pre-trained 모델
- 추후 Bert 배울 것도 사전학습 모델임.
(2) Pre-trained Word2Vec 모델 메모리 로드 - error 발생

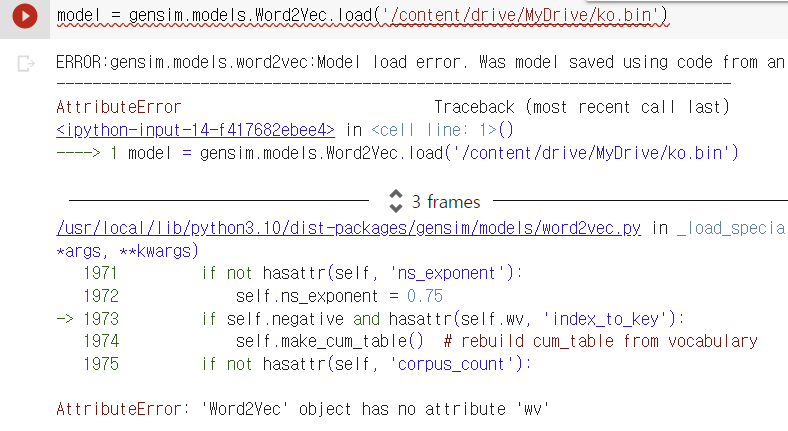
- 아직 해결하지 못함.
2. 한글 모델을 활용한 유사도 분석
1) 유서도 검색
(1) model.wv.similarity( ) 함수를 이용하여 유사도높은 단어 검색
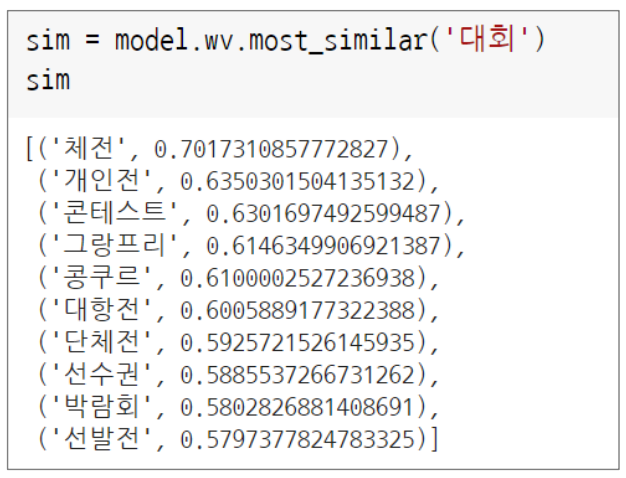
2) 단어 간 유사도 산출

3. 영문 모델
1) Pre-trained Word2Vec 모델 다운로드

- 구글 드라이브에 업로한 후에 그 위치에 참조 진행 추천.
2) Pre-trained Word2Vec 모델 메모리 로드

4. 영문 모델을 활용한 유사도분석
1) 유사어 검색
(1) model.most_similar( ) 함수를 이용하여 유사도 높은 단어 검색
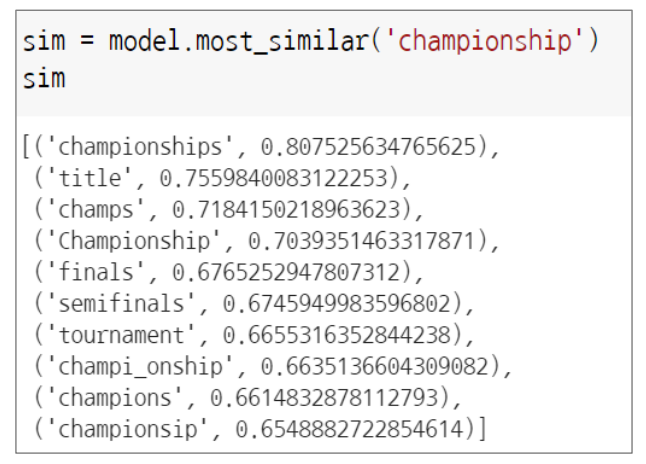
2) 단어 간 유사도 산출
(1) model.similarity( ) 함수를이용하여 두 단어 간 유사도 산출

'🥾 프로젝트 > (STEP)파이썬을 활용한 인공지능 자연어 처리' 카테고리의 다른 글
| 4-2회차) 자연어 처리를 위한 토픽 모델링 (0) | 2023.05.04 |
|---|---|
| 4-1회차) 자연어 처리를 위한 토픽 모델링 (0) | 2023.05.04 |
| 3-1회차) 자연어 처리를 위한 Word2Vec (0) | 2023.05.03 |
| 2-2회차) 자연어 처리 형태소 분석 (형태소 분석 사전활용) (0) | 2023.01.21 |
| 2-1회차) 자연어 처리 형태소 분석 (영문, 한글 형태소 분석) (0) | 2023.01.18 |



